Case Study: CALI — Competitive Agent Longitudinal Intelligence
Designed and led CALI, a longitudinal competitive intelligence system that tracks how customers actually experience, trust, and adopt AI shopping agents enabling faster, lower‑risk product decisions grounded in live market behavior.
Context & Problem
The problem
AI shopping agents are evolving rapidly across competitors.
Traditional research (one‑off usability tests, post‑launch surveys) is too slow and too fragmented to inform strategy.
Leadership lacked a continuous, customer‑grounded benchmark for value, trust, and adoption across AI agents.
Why this mattered
High uncertainty, high visibility product space
Late‑stage validation increased risk and rework
Decisions were often based on assumptions, anecdotes, or lagging indicators

My role
Principal researcher and architect of the CALI methodology
Defined the measurement framework, sampling strategy, and reporting cadence
Partnered with product, design, and leadership to align outputs to decision‑making needs
Scope
Competitive intelligence
Longitudinal behavioral research
Trust, adoption, and AI‑human interaction measurement
The Solution: What CALI Is
CALI is a flexible, longitudinal research system that:
Collects structured qualitative signals weekly
Applies a stable coding and measurement framework
Produces monthly and quarterly competitive intelligence on AI agents
What it delivers
A monthly pulse (current behavior + composite scores)
A quarterly synthesis (trends, narratives, implications)
A forecast of likely adoption and trust trajectories
How It Works (Method Overview)
Sampling
Flexible design:
Fresh participants each wave or
Longitudinal panel over time
Large recruitable pool (2.25M+)
Data collection
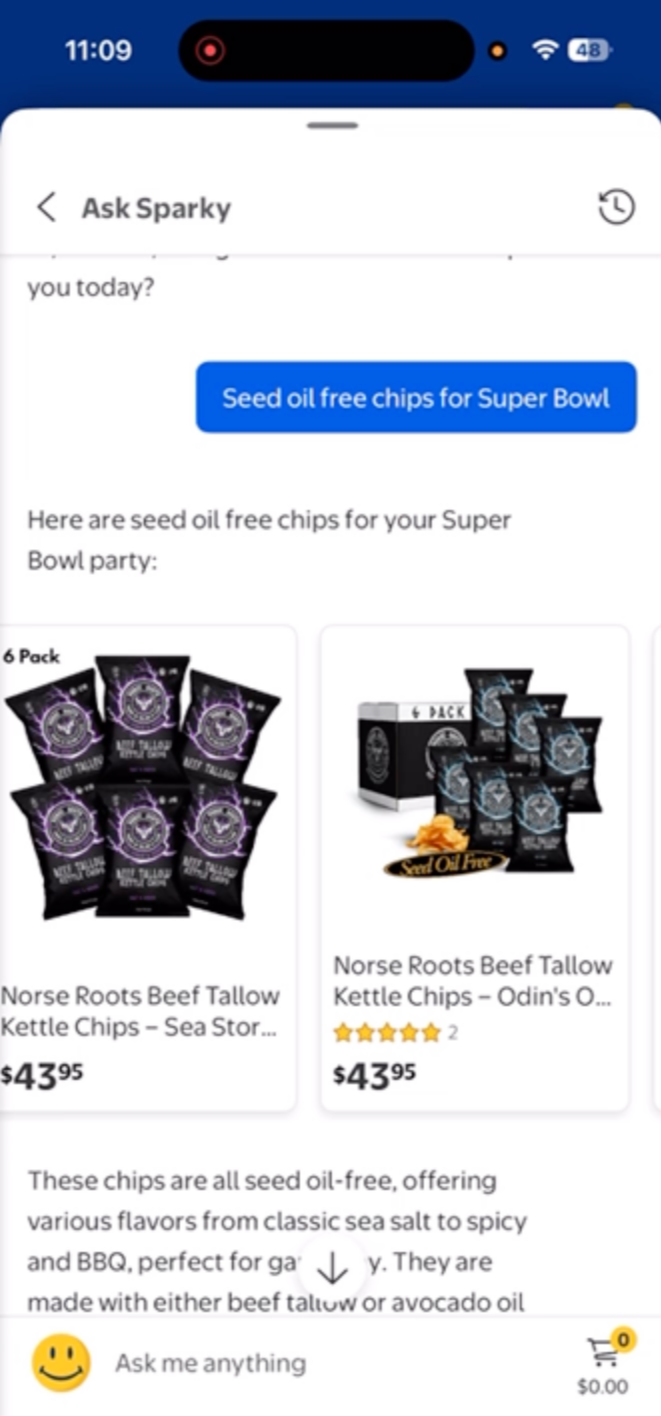
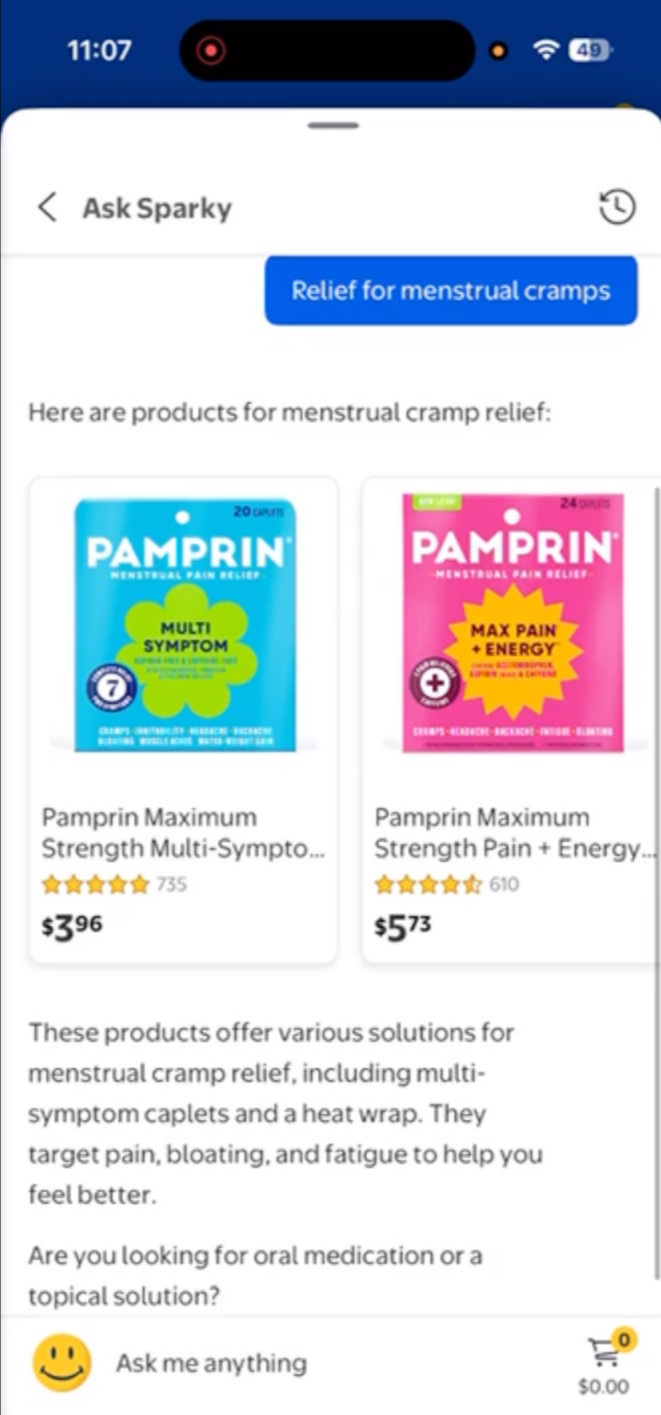
Participants walk through their last three real interactions with AI agents
Agents include competitive systems (e.g., Rufus, Sparky, Magic Apron)
Participants reference actual chat history (grounded recall)

Measurement
Structured, repeatable battery assessing:
Behavior
Experience quality
Trust and adoption outcomes
Synthesis
Monthly research memo on a predictable cadence
Centralized archive for continuity and learning
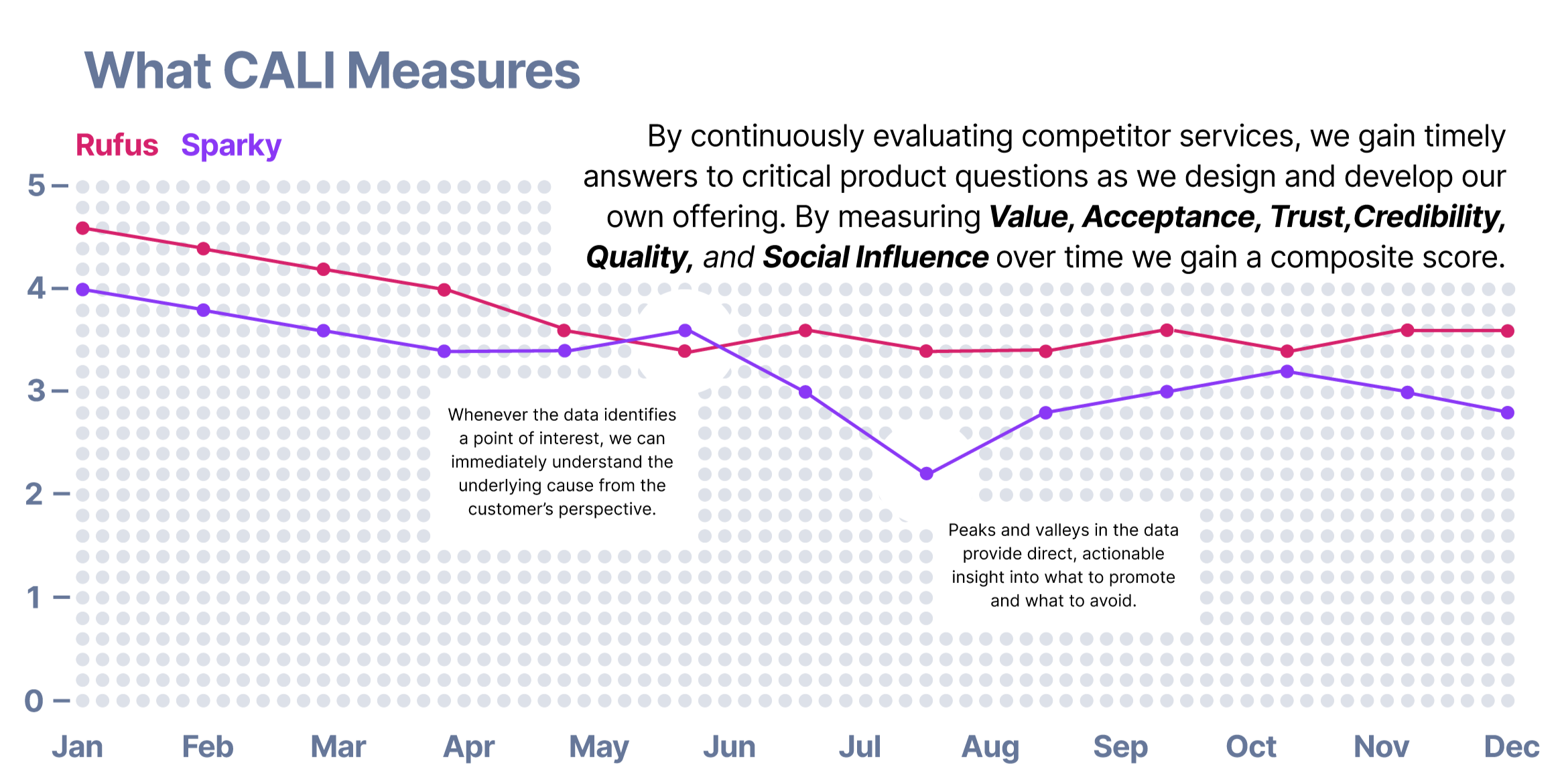
What CALI Measures (Core Framework)
Core dimensions
App value (Was it worth using?)
Acceptance (Will I use it again?)
Trusting stance toward AI
Information credibility
System quality (reliability, flexibility)
Social influence
Organizational assurance
Optional high‑value dimensions
Privacy comfort
Control and editability
Composite score
All dimensions compiled into a service composite score
Calculated as an unweighted mean
Enables clear, high‑level comparison across agents
Output Cadence & Cost Awareness
Reporting cadence
Monthly pulse: lightweight signals + composite scores
Quarterly synthesis: trends, patterns, implications
Recorded readouts + centralized archive
Resourcing
Baseline model:
15 participants/month
3 services
180 total participants/year 20k
~3% of monthly CX allocation
Easily scalable to biweekly or weekly
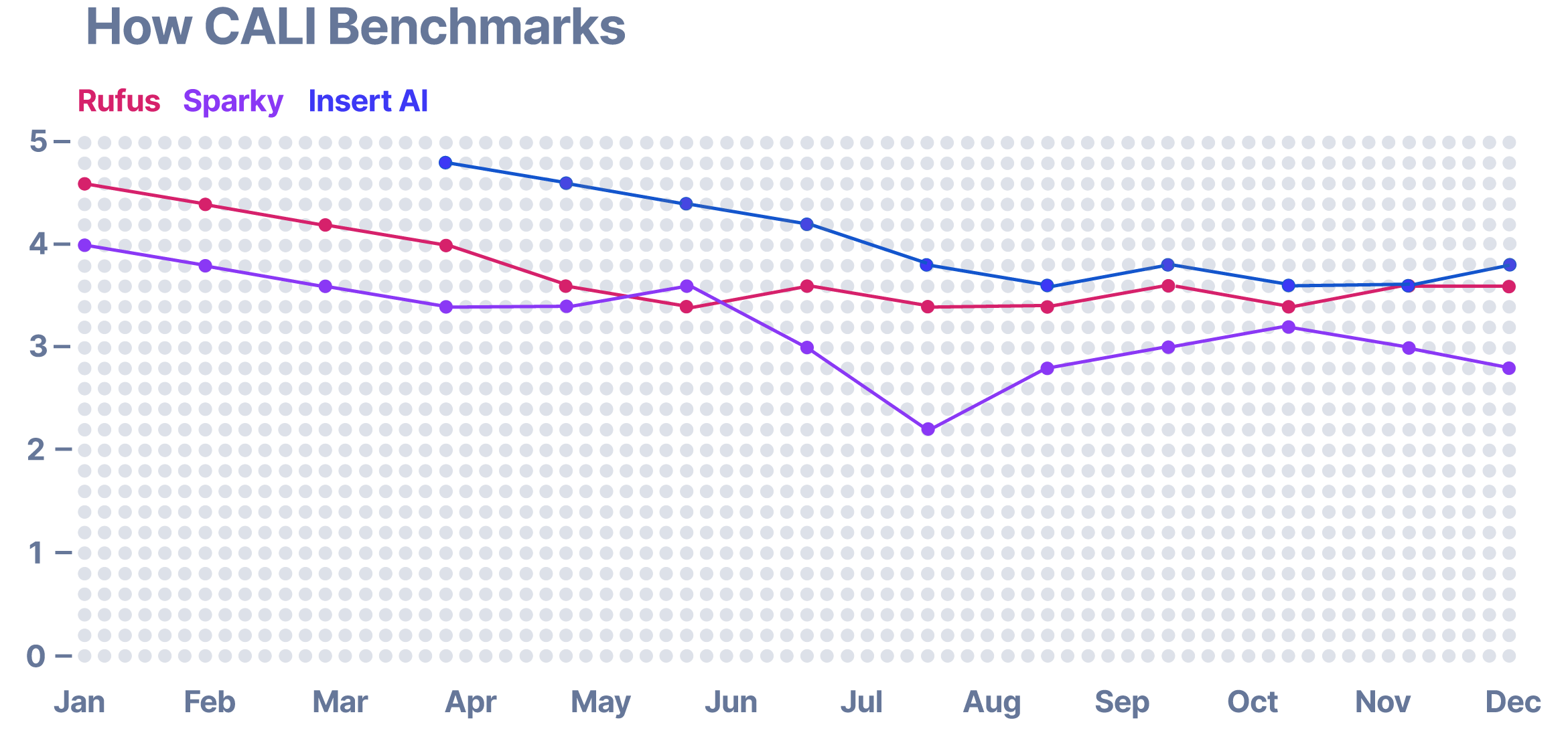
This approach allows us to see how customers actually use these services, where they succeed, and where friction occurs reducing reliance on assumptions and late‑stage validation. Over time, the same longitudinal signals create a clear benchmark, enabling us to directly plot our performance against the competition and identify areas of differentiation, parity, and risk. The result is faster, more confident product decisions grounded in live competitive reality.
Impact & Value
This is the most important section.
What CALI enables
Immediate diagnosis of why peaks and valleys occur
Early detection of trust, adoption, or quality risks
Reduced reliance on assumptions and late‑stage validation

Over time
Creates a living benchmark against competitors
Identifies differentiation, parity, and risk areas
Drives faster, more confident product decisions
Bottom‑line impact
Replaced episodic research with continuous competitive intelligence—grounded in real customer behavior.